前言
HashSet<T> 类是一个高性能的集合类,主要被设计用来存储对象,做高性能集运算,例如两个集合求交集、并集、差集等。从名称可以看出,它是基于 Hash 的,可以简单理解为没有 Value 的 Dictionary。
HashSet<T> 的一些特征如下:
1,HashSet<T> 中的值不能重复且没有顺序。 2,HashSet<T> 的容量会按需自动添加。
HashSet<T> 的优势和与 List 的比较
HashSet<T> 最大的优势是检索的性能,简单的说它的 Contains 方法的性能在大数据量时比 List<T> 好得多。曾经做过一个测试,将 800W 条 int 类型放在List<int> 集合中,使用 Contains 判断是否存在,速度巨慢,而放在 HashSet<int> 性能得到大幅提升。
在内部算法实现上,HashSet<T> 的 Contains 方法复杂度是 O(1),List<T> 的 Contains 方法复杂度是 O(n),后者数据量越大速度越慢,而 HashSet<T> 不受数据量的影响,所以 HashSet<T> 的查询效率有着极大的优势。
所以在集合的目的是为了检索的情况下,我们应该使用 HashSet<T> 代替 List<T>。
比如要对用户注册时,输入的邮箱做唯一性检查,而当前已注册的邮箱数量达到 10 万条,如果使用 List<T> 进行查询,需要遍历一次列表,时间复杂度为 O(n),而使用 HashSet<T> 则不需要遍历,通过哈希算法直接得到列表中是否已存在,时间复杂度为 O(1),这是哈希表的查询优势。
此外, HashSet<T> 的 Add 方法返回 bool 值,在添加数据时,如果发现集合中已经存在,则忽略这次操作,并返回 false 值。而 Hashtable<T> 和 Dictionary<T> 碰到重复添加的情况会直接抛出错误。
性能实验
前面的文字都是复制粘贴的,没办法人家写的太好了,我就做个实验验证一下好了 😂。
using System; using System.Collections.Generic; using System.Diagnostics; namespace Hashset_test { class Program { static void Main(string[] args) { Stopwatch sw = new Stopwatch(); Console.WriteLine("List<int>"); sw.Start(); List<int> list = new List<int>(); for (int i = 0; i < 10000000; i++) { list.Add(i); } sw.Stop(); Console.WriteLine("插入总耗时 {0} ms", sw.Elapsed.TotalMilliseconds); sw.Restart();if (list.Contains(5)) { };sw.Stop(); Console.WriteLine("查询 5 耗时 {0} ms", sw.Elapsed.TotalMilliseconds); sw.Restart();if (list.Contains(555555)) { };sw.Stop(); Console.WriteLine("查询 555555 耗时 {0} ms", sw.Elapsed.TotalMilliseconds); sw.Restart();if (list.Contains(9999999)) { };sw.Stop(); Console.WriteLine("查询 9999999 耗时 {0} ms", sw.Elapsed.TotalMilliseconds); sw.Restart();if (list.Contains(5)) { };sw.Stop(); Console.WriteLine("查询 5 耗时 {0} ms", sw.Elapsed.TotalMilliseconds); Console.WriteLine("\r\nHashSet<int>"); sw.Restart(); HashSet<int> hashset = new HashSet<int>(); for (int i = 0; i < 10000000; i++) { hashset.Add(i); } sw.Stop(); Console.WriteLine("插入总耗时 {0} ms", sw.Elapsed.TotalMilliseconds); sw.Restart();if (hashset.Contains(5)) { };sw.Stop(); Console.WriteLine("查询 5 耗时 {0} ms", sw.Elapsed.TotalMilliseconds); sw.Restart();if (hashset.Contains(555555)) { };sw.Stop(); Console.WriteLine("查询 555555 耗时 {0} ms", sw.Elapsed.TotalMilliseconds); sw.Restart();if (hashset.Contains(9999999)) { };sw.Stop(); Console.WriteLine("查询 9999999 耗时 {0} ms", sw.Elapsed.TotalMilliseconds); sw.Restart();if (list.Contains(5)) { };sw.Stop(); Console.WriteLine("查询 5 耗时 {0} ms", sw.Elapsed.TotalMilliseconds); Console.ReadKey(); } } }
实验结果:
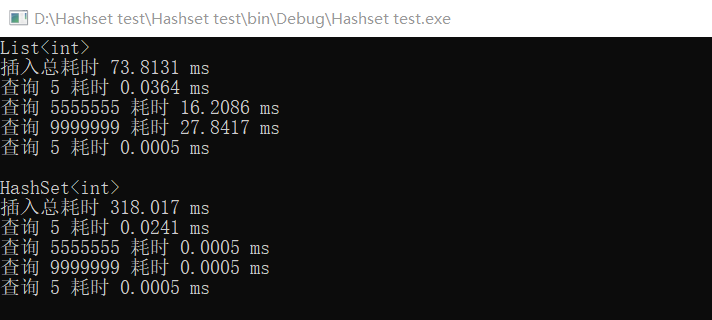
可以看到
1,List<T> 查询虽然慢,但是插入很快。而 Hashset<T> 查询快,但是插入慢。
2,List<T> 查询的时候是从前往后遍历,所以查的数据越靠后需要的时间越长。但是奇怪的是,第二次查询 5 的速度比第一次查询 5 的速度很快多。难道是有缓存?
3, Hashset<T> 的查询速度与数据的顺序无关,都很快。但是和 List<T> 一样,也是第二次查询同样的数据会快很多。
集合运算
IntersectWith (IEnumerable other) (交集)
UnionWith (IEnumerable other) (并集)
ExceptWith (IEnumerable other) (排除)
例如 public void IntersectWithTest() { HashSet<int> set1 = new HashSet<int>() { 1, 2, 3 }; HashSet<int> set2 = new HashSet<int>() { 2, 3, 4 }; set1.IntersectWith(set2); foreach (var item in set1) { Console.WriteLine(item); //输出:2,3 } }